Linux | awk
awk
- 파일로부터 레코드(record)를 선택하고, 선택된 레코드에 포함된 값을 조작하거나 데이터화하는 것을 목적으로 사용하는 프로그램
- 지정된 파일로부터 데이터를 분류한 다음, 분류된 텍스트 데이터를 바탕으로 패턴 매칭 여부를 검사하거나 데이터 조작 및 연산 등의 액션을 수행하고, 그 결과를 출력하는 기능을 수행
- awk는 기본적으로 입력 데이터를 라인(line) 단위의 레코드(record)로 인식함 => 각 레코드에 들어 있는 텍스트는 공백 문자(space, tab)로 구분된 필드(field)들로 분류됨
- 식별된 레코드 및 필드의 값들은 awk 프로그램에 의해 패턴 매칭 및 다양한 액션의 파라미터로 사용됨
1) 문법
- awk로 시작하는 경우
# awk 'PATTERN' 파일명
# awk '{PATTERN}' 파일명
# awk '/PATTERN/ {ACTION}' 파일명
- 명령어의 결과를 이용한 경우
# command | awk 'PATTERN'
# command | awk '{ACTION}'
# command | awk 'PATTERN {ACTION}'
* -F 필드 구분자 지정 : 필드 구분자의 기본값은 공백이므로 다른 구분자를 사용하고 싶을 때 옵션 사용
ex) # awk -F: '{print $1}' /etc/passwd | grep testuser
-> 필드 구분자를 콜론으로 지정

- 기본 구분자는 공백이기 때문에 옵션 미사용 시 한 줄이 그대로 출력 (공백이 없기 때문에 한 행으로 인식)
- 필드 구분자를 콜론으로 지정 시 사용자명이 첫 번째 행으로 구분되어 사용자명만 출력
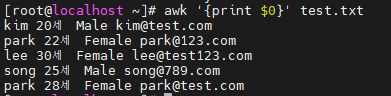
2) 사용 예시



** sed : 문자열을 대체/치환하는 명령어
# sed 's/a/b/' : a를 b로 치환


